The Delicious Course of Hadoop
“From WordCount.java to Data Pipeline”
 Delicious Course of Hadoop
Delicious Course of Hadoop
Hadoop, HDFS and MapReducePermalink
Apache Hadoop is a collection of open-source software utilities that facilitate using a network of many computers to solve problems involving massive amounts of data and computation.
Hadoop is really useful for analysing logs. For example, back in 2009 there were already a large portion of non-progammers at Facebook using HiveQL(Hive Query Language) to analyse their logs. For companies like TaoBao/LinkedIn/Amazon, people use this kind of technology to filter large volume of data (淘宝: 自定义筛选/self-defined search; LinkedIn: people you might know; Amazon: filter recommendation).
So how does it work?Permalink
A simple example here:
Supose having 1TB SQL file, we want to use regular experssion to filter the target information without importing into database. But if we just use grep or write some scripts running locally to check each row, it will take forever considering the performance of single computer or the limitations of the hardware.
This’s when distributed computing comes in. Just as its name suggests, single task is distributed to multiple machines to run concurrently. Interestingly enough, the programmers do not actually need to know the distributed algorithms to write the scripts(never hurt to know:)) Instead, they can just defined the interface by MapReduce, then Hadoop takes the rest of it.
So what happens is, after data is imported into HDFS, the map and reduce fuction are defined to match results using regex(normally key is each row and value is the content)
HDFSPermalink
Following definition is directly taken from here
The Hadoop Distributed File System (HDFS) is the primary data storage system used by Hadoop applications. It employs a NameNode and DataNode architecture to implement a distributed file system that provides high-performance access to data across highly scalable Hadoop clusters.
HDFS is the key part of many Hadoop ecosystem as it provides a reliable means for managing pools of big data and supporting related big data analysis applications.HDFS is closely coupled with MapReduce, a programmatic framework for data processing.
When HDFS takes in data, it breaks the information down into separate blocks and distributes them to different nodes in a cluster, thus enabling highly efficient parallel processing.
Here’re some good things:
-
highly fault-tolerant. The file system replicates, or copies, each piece of data multiple times and distributes the copies to individual nodes, placing at least one copy on a different server rack than the others. As a result, the data on nodes that crash can be found elsewhere within a cluster. This ensures that processing can continue while data is recovered.
-
master/slave architecture. HDFS is one primary components of Hadoop cluster and HDFS is designed to have Master-slave architecture.
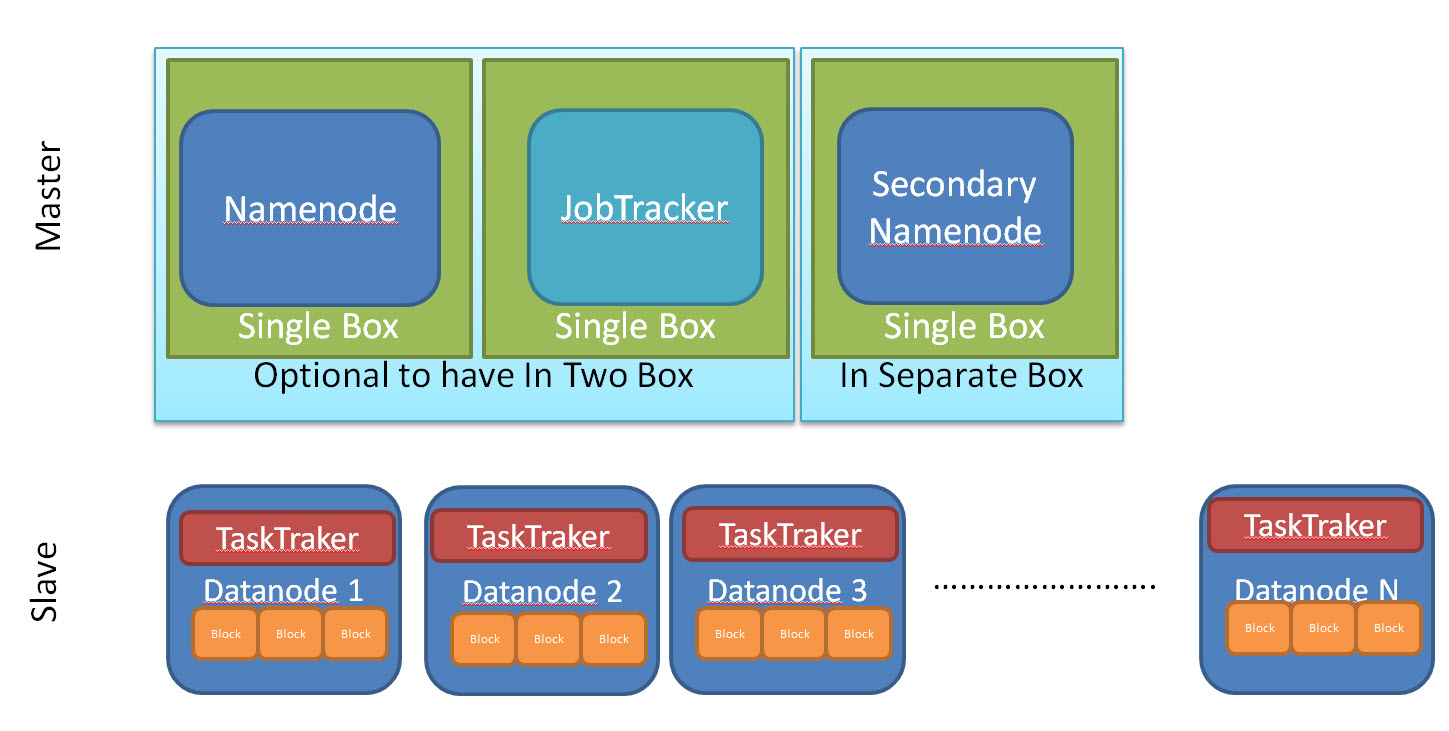 Master Slave Architecture of Hadoop
Master Slave Architecture of Hadoop
Master: Namenode, JobTracker
Slave: {DataNode, TaskTraker}, ….. {DataNode, TaskTraker}
-
The Master (NameNode) manages the file system namespace operations like opening, closing, and renaming files and directories and determines the mapping of blocks to DataNodes along with regulating access to files by clients
-
Slaves (DataNodes) are responsible for serving read and write requests from the file system’s clients along with perform block creation, deletion, and replication upon instruction from the Master (NameNode).
MapReducePermalink
Using the philosophy of Divide and Conquer
Map/Reduce is also primary component of Hadoop and it also have Master-slave architecture
Master: JobTracker
Slaves: {tasktraker}……{Tasktraker}
-
Master {JobTracker} is the point of interaction between users and the map/reduce framework. When a map/reduce job is submitted, Jobtracker puts it in a queue of pending jobs and executes them on a first-come/first-served basis and then manages the assignment of map and reduce tasks to the tasktrackers. Every Hadoop group can only have one JobTracker, located in master.
-
Slaves {TaskTracker} execute tasks upon instruction from the Master {Jobtracker} and also handle data motion between the map and reduce phases.
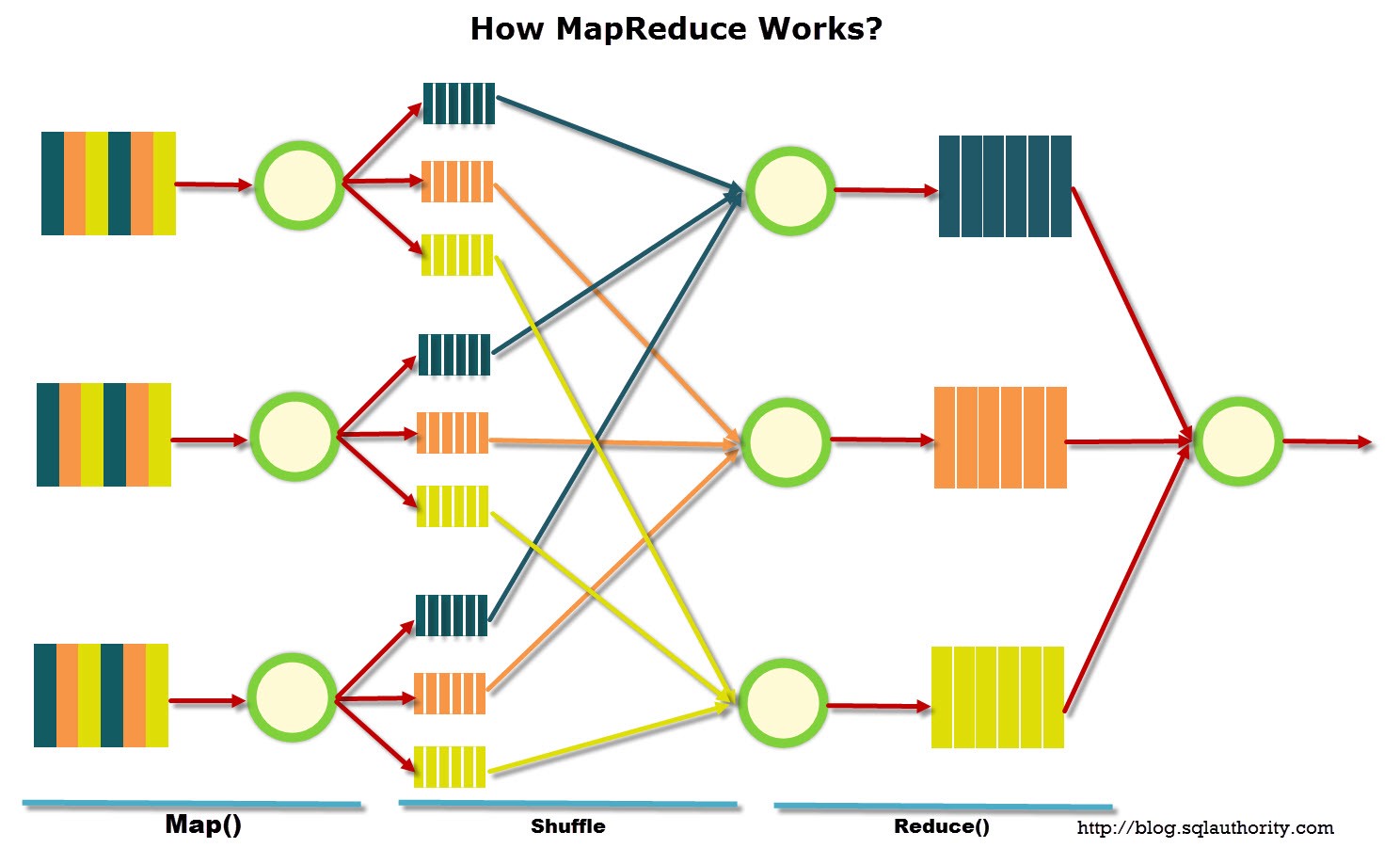 How MapReduce works/small>
How MapReduce works/small>
So generally, Hadoop = HDFS(file system, data storage) + Mapreduce(data processing).
Pros of HadoopPermalink
-
Data Agility. Hadoop is “schema on read”, as opposed to most traditional RDBMS which needs a strict schema definition before any data can be ingeted into them. when a new data field is needed, one is not required to go through a lengthy project of schema redesign and database migration in production, which can last months.
-
Cost Effective. It is a cost-effective solution for data storage purposes. This helps in the long run because it stores the entire raw data generated by a company. If the company changes the direction of its processes in the future, it can easily refer to the raw data and take the necessary steps. This would not have been possible in the traditional approach because the raw data would have been deleted due to increase in expenses.
-
Speed. Since the tools used for the processing of data are located on same servers as the data, the processing operation is also carried out at a faster rate. Therefore, you can processes terabytes of data within minutes using Hadoop.
-
Multiple copies. Hadoop automatically duplicates the data that is stored in it and creates multiple copies.
Cons of HadoopPermalink
-
Small Data Concerns. Hadoop is not so suitable for small data functions so it cannot efficiently perform in small data environments.
-
Lack of Security Measures. The secuirty measures in Hadoop is disabled by default. Data administrator should take measures to secure the data.
-
Risky Functions. Framework built on Java is easily exploited.
My first MapReduce program – WordCount.javaPermalink
Every time we learn a new language, the first output is Hello Word, but in Hadoop, the most common program is WordCount.java. First time I wrote this was during my college CS electives, Data Intensive Computing. We can say it’s the easiet and clearest MapReduce program, only containing 3 hava files used for mapping, shuffeling and reducing.
These java files all locate in /src/.
TokenizerMapper.javaPermalink
package com.lisong.hadoop;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
IntWritable one = new IntWritable(1);
Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException,InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
IntSumReducer.javaPermalink
package com.lisong.hadoop;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,InterruptedException {
int sum = 0;
for(IntWritable val:values) {
sum += val.get();
}
result.set(sum);
context.write(key,result);
}
}
WordCount.javaPermalink
package com.lisong.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if(otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "wordcount");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
After debugging, first compile, then package and last, execution.
1. CompilePermalink
$ javac -classpath /home/hadoop/hadoop/share/hadoop/common/hadoop-common-ver.jar:/home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-ver.jar:/home/hadoop/hadoop/share/hadoop/common/lib/commons-cli-ver.jar -d classes/ src/*.java
2. PackagePermalink
jar is the packaging tool in JDK. The output is wordcount.jar.
$ jar -cvf wordcount.jar classes
3. ExecutePermalink
Place the file in HDFS first!
$ hadoop/bin/hadoop fs -ls / # check folder
$ hadoop/bin/hadoop fs -put input /hbase # copy file to HDFS
$ hadoop/bin/hadoop jar wordcount_01/wordcount.jar com.lisong.hadoop.WordCount /hbase/input /hbase/output
# run
$ hadoop/bin/hadoop fs -ls /hbase/output
$ hadoop/bin/hadoop fs -cat /hbase/output/part-r-00000 # check output
Data PipelinesPermalink
What is data pipelines?Permalink
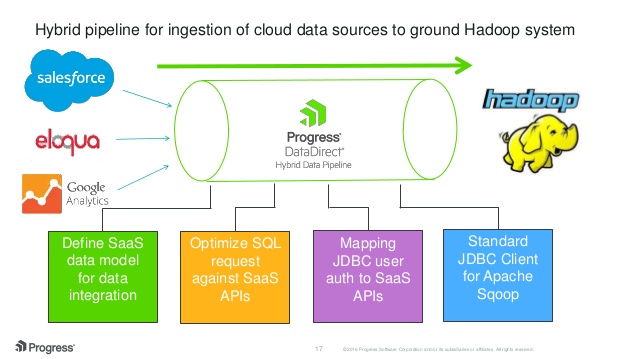 Example: Hybrid Data Pipeline for Salesforce and Hadoop
Example: Hybrid Data Pipeline for Salesforce and Hadoop
As daily data is becoming more diverse, complex and large-scale, it is necessary to build data pipelines to help improve working efficiency. So what is data pipeline?
In computing, data pipeline is a set of data processing elements connected in series, where the output of one element is the input of the next one. The elements of a pipeline are ofen executed in parallel or in time-sliced fashion.
For better understanding, we can treat the dara pipeline as a tunnel that connects the entire data system while the data is what goes inside it.
Leave a comment