Understand data & Build reliable, scalable and maintable applications
Designing Data Intensive Applications(DDIA) has been praised by many people in the industry as a great book to bridge knowledge gap between theories of data systems and practical engineering. Mastering tradeoffs of each technology and apply them to solve real world problems take huge effort and constant learning; So I’m writing this post for my reading notes and some takeaways ;-)
Part 1. Foundations of Data Systems
Reliable, Scalable, and Maintainable Applications.
- compute-intensive: limited by CPU power;
- data-intensive: volume, complexity and quantity of the data(sometimes plus constantly advancing speed);
Data-Intensive Applications usually consists following functions:
- storage: databases;
- caches: remember results of expensive operations to save cost;
- search indexes: allow searching using keywords or other filtering methods;
- stream processing: Send a message to another process, to be handled asynchronously;
- batch processing: Periodically crunch a large amount of accumulated data;
Why we talk about data systems generally?
- The boundaries between the categories are becoming blurred. For example, Redis(datastore that can be used as message equeues) and Apache Kafka(message queues with database-like durability gurantees)
- applications are requiring different functionalities a single tool cannot meet. So people usually just break tasks down into small pieces, solving each one using single tool, and then glue them back using application code.
For example, it’s usually application code’s job to sync all search indexes and caching with the primary db. Once all development finished, combining several tools together specially for one specific task becomes not just application developing, but also data system design
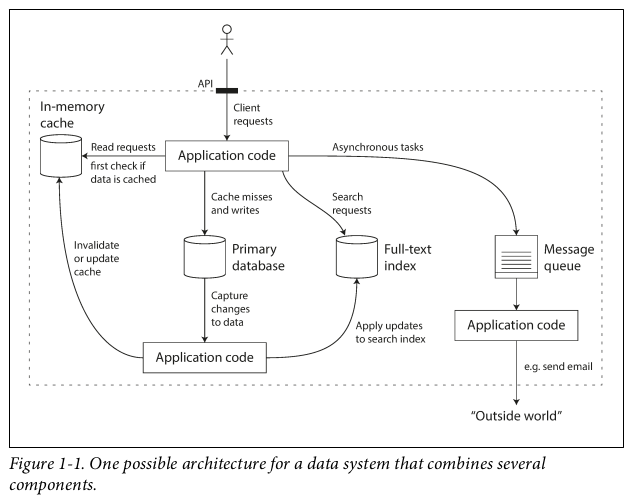
Reliability
System can continue to work correctly even in the face of adversity.
Fault-tolerant / resilient: able to predict faults and can cope with them(certain types of course).
Many critical bugs are actually due to poor error handling. So to increase the rate of faults, we can trigger them deliberately(e.g. randomly killing individual processes without warning) to ensure that fault-tolerance machinary is continually exercised and tested. And we generally prefer tolerating faults over preventing faults.
Netflix: Chaos Monkey, a resiliency tool that help applications tolerate random instance failures by randomly terminates vm instances and containers that run inside of your production env, exposing engineers to failures more frequently to incentivize them to build resilient services.
| Faults | Solutions |
|---|---|
| hardware faults | Hard disks crash, faulty RAM, blackout power grid, wrong network cable unplugged 1. add rebundancy components to the individual hardware in order to reduce failure rate. Disks may be set up in a RAID configuration, servers may have dual power supplies and hot-swappable CPUs, and datacenters may have batteries and diesel generators for backup power. 2. system patches so downtime is for one node one time |
| software erros | systematic error within the system, harder to predict, cause more erros since nodes system are correlated acrosee nodes no quick solutions. Requires careful thinkings, measuring, monitor, analyzing |
| human errors | human tend to be unreliable even though intentions are good, leading cause of internet error outages 1. Design well: abstractions, APIs, admin interface…. 2. Decouple most-mistakes place: providing sandbox envs for exploring and experiment safely using real data. 3. Test all levels: unit testing -> whole-system integration tests -> automated testing 4. Quick recovery: fast roll back configuration changes, roll out new code gradually, provide tools to compute data. 5. Set up Monitoring: set up performance metrics and error rates(telemetry) 6. Implement training & management |
Scalability
Scalability is the term we use to describe a system’s ability to cope with increased load – System can deal with the growth in data volume, traffic volume or complexity.
Describe Current Load
There are some load parameters and the best choice of the parameters depend on the system architecture: it may be requests per second to a web server, the ratio of reads to writes in a database, the number of simultaneously active users in a chat room, the hit rate on a cache, or something else.
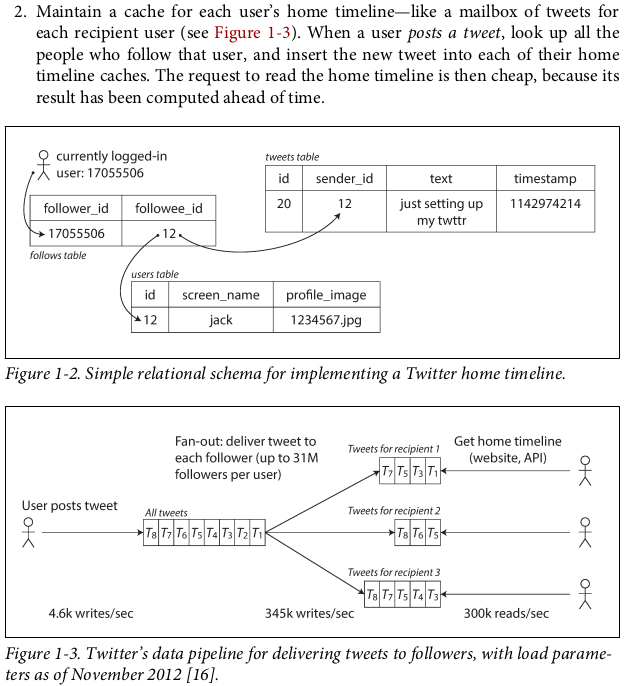
One example from Twitter:
the bottleneck of the scalability is not about the tweet volume but the fan-out(A term borrowed from electronic engineering, where it describes the number of logic gate inputs that are attached to another gate’s output. In transaction processing systems, we use it to describe the number of requests to other services that we need to make in order to serve one incoming request.)
As shown, it’s better to do more work at write time and less at read time. But this also means posting a tweet requires extra work due to write to caches. And such distribution of followers per user is a key load parameter for discussing scalability.
Now the Twitter is moving to a more hybrid approach by combining both: Most users’ tweets continue to be fanned out to home timelines at the time when they are posted, but a small number of users with a very large number of followers (i.e.,celebrities)are excepted from this fan-out. Tweets from any celebrities that a user may follow are fetched separately and merged with that user’s home timeline when it is read, like in approach 1. This hybrid approach is able to deliver consistently good performance.
1. Describe Performance
-
Throughput: the number of records we can process per second, or the total time it takes to run a job on a dataset of a certain size. Usually for batch processing system.
-
Latency & Response Time: Response time is the time between a client sending a request and receiving a response (includes network delays and queueing delays). Latency is the duration that a request is waiting to be handled—during which it is latent, awaiting service. Usually for online systems.
Since response time varies each time the user makes the request, we need to think of it as distribution of values. Usually it’s better to use percentiles. For example we sort the list of response time from fastest to slowest, the median would be a good metric to know how long users typically have to wait.
Same goes for checking the outliers: we just use a much higer percentiles(p95, p99 and p999 usually, meaeining how many thresholds are faster than particular thresholds), and high percentiles of response times, or tail latencies, are important because they directly affect the user experience of the service. Usually clients experiening bad response times are exactly those made most data storage/purchases, aka. most valuable customers. However, ensuring optimized response times(e.g. 99.999 percentiles) also means generating less revenue and thus does not yield enough benefit for the service providers’ sake.
Service Level Objects(SLOs) and Service Level Agreements(SLAs) ofen use percentiles to define the expected performance and availability of a service.
For example, customers can demand a refund if SLAs are not met.
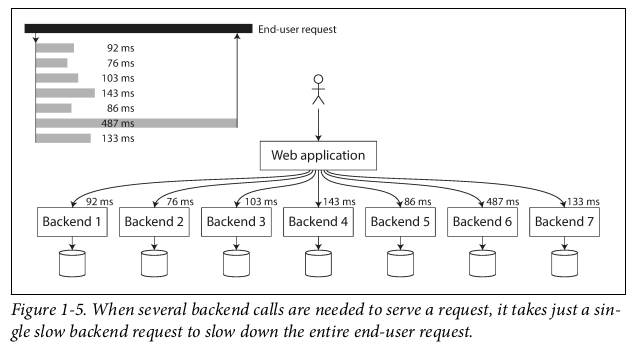
Queueing delays ofen account for a large part of the response time at a high percentiles. As a server can only process a small number of things in parallel(For exmaple, limited by CPU cores). head-of-line blcoking refers exactly to a situation when a few slow requests hol up the processing of subsequent requests even though these subsequents are fast to process. So it’s important to measure response times on the client side.
Tail Latency Amplification: Even if only a small percentage of backend calls are slow, the chance of getting a slow call increases if an end-user request requires multiple back‐end calls, and so a higher proportion of end-user requests end up being slow.
2. Approaches for Loading
Scale up / vertical Scaling: moving to more powerful machines.
Scale out / Horizontal Scaling: distributing the load across multiple smaller machines. Also known as shared-nothing architecture.
In real life, systems are elastic, meaning they can automatically add computing resource if detects a load increase(useful if loads are highly unpredictable); wheras others are scaled manually.
So far, there’s no magic scaling sauce – a generic, one-size-fits-all scalable architecture. Systems at this scale are usually designed specifically and problems contain the volume of reads, the volume of writes, the volume of data to store, the complexity of data, the response time requirements, the access patterns, or usually some mixture of all plus some other issues.
Maintainability
Many different people(engineering & operations) can both maintain current behaviour and adapt system to new use cases, and they should be work productively.
FANTASTIC Lagacy Code: every legacy in unpleasant in its own way.

The majority of the cost of software is not initial development but maintenance - fixing bugs, keepign systems operational, investigating failures and more. It’s hard to give general recommendations to deal with all legacy systems but we can follow these principles to avoid troubles as much as we can:
| principles | details |
|---|---|
| Operabiliy | Good data systems should be able to do following to make operation teams’ life easier: Providing visibility into the runtime behavior and internals of the system, with good monitoring Providing good support for automation and integration with standard tools Avoiding dependency on individual machines (allowing machines to be taken down for maintenance while the system as a whole continues running uninterrupted) Providing good documentation and an easy-to-understand operational model(“If I do X, Y will happen”) Providing good default behavior, but also giving administrators the freedom to override defaults when needed Self-healing where appropriate, but also giving administrators manual control over the system state when needed Exhibiting predictable behavior, minimizing surprises |
| Simplicity | able to manage complexity. Abstraction: one of the best way to remove accidental complexity(e.g. SQL is an abstraction that hides complex on-disk and in-memory data structures, concurrent requests from other clients and inconsistencies after crashes, high level language hides machine code, CPU registers, and syscalls) explosion of the state space tight coupling of modules tangled dependencies inconsistent nameing and terminology hacks for performance more… |
| Evolvability | /Extensibility/Modifiability/Plasticity:Agile working patterns |
Map of Dbs
This section covers a range of data models for data storage and querying.
Data Models & Query Language
Relational VS Document
Best-known data model today is probably SQL, ased on the relational model proposed by Edgar Codd in 1970. data is organized into relations (called tables in SQL), where each relation is an unordered collection of tuples (rows in SQL).
| Model types | details |
|---|---|
| Relational Model | roots of RDBMS lies in business data process on mainfarme pcs in 60 - 70s: typically transaction processing (entering sales or banking transactions, airline reservations, stock-keeping in warehouses) and batch processing (customer invoicing, payroll, reporting). |
| Document Model | NoSQL in 2010s occurs in need of 1. greater scalability than relational databases including very high write throughput 2. A widespread preference for free and open source software over commercial database products 3. Specialized query operations that are not well supported by the relational model Frustration with the restrictiveness of relational schemas, and a desire for a more dynamic and expressive data model |
Query for Data
Graph-Like Data Models
Storage & Retrieval
Part 2. Distributed Data
Part 3. Derived Data
Blah Blah Blah
起源:
和某著名电商网站的大佬说自己经常用Hadoop,结果被随意的几个问题血虐
和某著名短视频app的大佬说自己一个人写过一个全栈网站,结果被随意的几个问题血虐
和某地区记者说自己跑得快,结果..不好意思跑题了…
结论:
吹水需谨慎, 渣渣还是要做渣渣该做的事
Martin Kleppmann写的 Design Data Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems 是本被很多大佬推荐过的神书,之前一直没时间明明是懒得读, 最近临近final反而神奇地爆发了阅读欲望明明是不想赶due。
去年上过一门Data Intensive Computing, 粗略地学了学数据处理框架和流程然后去Kaggle假装了下Data Science入门, 但是对总体工程数据的应用完全没有深入的认知。晃眼一看大三马上就要结束了, Year3给我最大的教训就是(也是书里作者说过的):“You should know more than just a few Buzzwords”。 就好比使用Linux, 用Linux desktop开浏览器刷油管是“在使用Linux”(好像又是我),用Linux真正地造轮子也是“在使用Linux”。归根结底,不是说你用过什么,而是真正了解多少。这也是我开始阅读这本书的动力。把读书笔记发在博客,就当做个记录和大家交流(然後几年后回来看还会多少)
“Just keep Learning”, 与大家共勉:)
Leave a comment