Streaming Systems: Data Processing, Watermarks & Advanced Windowing
This post is my reading notes of Part 1, The Beam Model(Chapter 1-4) from the book, which covers the high-level batch, streaming data processing model called Apache Beam;
Streaming 101
1. What is streaming?
Streaming System
A type of data processing engine designed with infinite datasets in mind.
Shape of a dataset
| Cardinality | Consitution | |
|---|---|---|
| definition | its size, with the most salient aspect of cardinality being whether the given dataset is infinite or finite; | physical manifestation, which defines the way one can interact with the given dataset; |
| types | - Bounded data: a dataset that is finite in size; - Unbounded data: a dataset that is infinite in size(at least theoretically); |
Two primary constitutions of importance is: - Table: A holistic view of a dataset at a specific point in time. SQL systems have traditionally dealt in tables; - Stream: An element-by-element view of the evolution of the dataset over time. The MapReduce lineage of data processing systems have traditionally dealt in streams. |
Why stream processing is important?
- business requires more timely insights & streaming achieves lower latency;
- easier to manage massive, unbounded dataset that are increasingly common nowadays;
- more consistent, predictable comsumption of resources since the incoming data arrival is spread out evenly;
2. Background
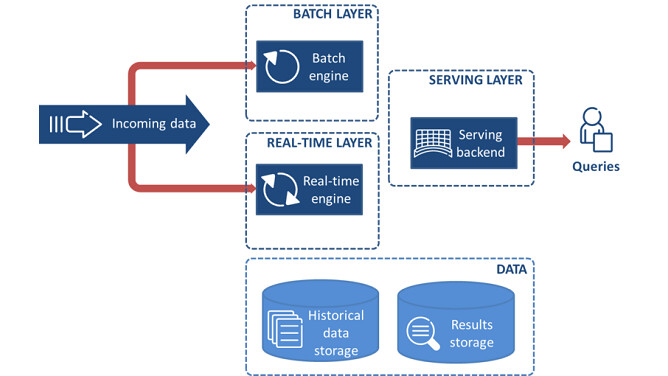
Lambda Architecture
Lambda Architecture: a data processing architecture that has stream system to produce low-latency, inaccurate(either bcoz of approximation algorithm or the system itself does not provide correctness)/speculative results and batch system to provide eventual correct results;
Some links:
The reason that the Lambda Architecture is successful is it could actually provide some good results even though the correctness is a bit of letdown; However, it is a lot of work to maintain two independent versions of pipeline and merge the results in the end;
Some people argue against the necessity of dual-mode execution because of the issue of repeatability of using a replayable system(like Kafka) so they propose the Kappa Architecture, which runs a single pipeline using a well designed & built system(like Apache Flink);
| Lambda Architecture | Kappa Architecture |
|---|---|
 |
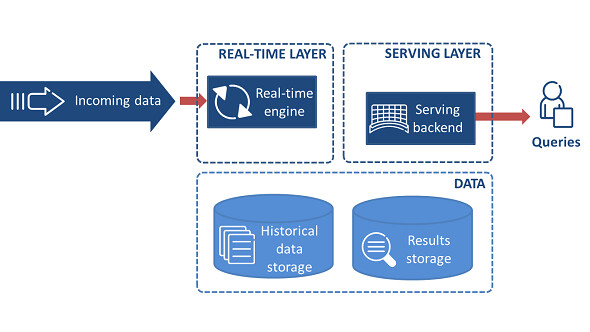 |
Lambda vs Kappa Architecture
Usually if the real-time algorithm and batch algorithm have different outputs, meaning batch & real-time layers cannot be merged, then must use Lambda Architecture;
TBC
Batch vs Streaming Efficiency
- Batch: high-latency, higher-efficiency;
- Streaming: low-latency, lower-efficiency;
But for streaming system to achieve the same performance of batch systems, we only need to focus on 2 things:
- correctness: because strong consistency is required for exactly-once processing, which is required for correctness, which is requirerd to meet batch system’s level of performance. (ref: Why local state is a fundamental primitive in stream processing)
- tools for reasoning about time: essential for dealing with unbounded, unordered data of varying time skew;
Event Time vs Processing Time
| — | Event Time | Processing Time |
|---|---|---|
| Definition | the time at which events actually occured | the time at which events are observed in the system |
Some variables that can affect the skew between event time and processing time;
- shared recource limitations like network congestion, network partitions, shared CPU, etc;
- software causes like distributed system logic, contention, etc;
- features of the data like distribution, variance in throughput, variance in disorder;
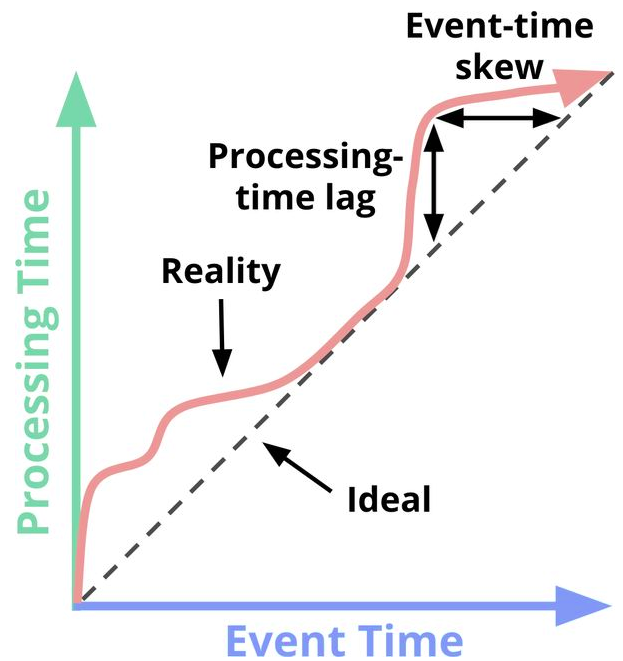
Because the overall mapping between event time and processing time is not static(the lag/skew can vary arbitraily over time), we cannot analyze data soely by the observed time;
To cope with such unfortunate design for unbounded data of many systems, we implement the windowing of the incoming data, meaning chopping up a dataset into finite pieces along temporal boundaries;
Data Processing Patterns
- Bounded Data
pretty straightforward, run the dataset through some data processing engine to get a strcutured dataset with greater inherent value;
-
Unbounded Data
-
Fixed windows
Most common way, repeatedly run a batch engine to process input data which is windowed into fixed-size windows(separate data source, sometimes called tumbling windows);
- Sessions
Leave a comment